

Jakub MarciniakDevOps EngineerEwork Group
Serverless architecture in practice
Check how to avoid managing your own server and infrastructure by using Serverless Architecture.
Usually, when an application is deployed onto a server, some level of control is retained, even if this is achieved only by means of HTTP requests. An application owner has to, above all, manage server resources, monitor infrastructure, carry out about access control and many others. With the power of the Serverless concept, however, the stack setup and infrastructure management can be avoided altogether.
The idea is to manage these resources for you. Such a developer delivers code, sets up triggers, permissions, logs and covers expenses (and is compensated for it).
Serverless is called FaaS (Function as a Service) which is an accurate definition. There are two types of Serverless, both cover the same activities:
- managed cloud FaaS - delivered by cloud providers like AWS or GCP
- open source FaaS - Seemingly delivered by a community as an open source project, however a cloud administrator or a DevOps engineer still has to provide the resources to run an FaaS server.
Many developers still have trouble choosing between them. The answer is not easy and depends on many factors.
In this article, I hope (I intend) to explain how to and when to use AWS Lambda - FaaS delivered with AWS.
What are the costs of Serverless?
There are no fixed prices. To properly estimate the costs of Serverless, we need to map out our needs and take into account variables such as required performance, execution time, number of requests etc. and then calculate our actual budget. Even simple functions can consume huge amounts of money when written incorrectly. I speculate that this is the reasoning behind the limits of cloud solution usage imposed by cloud providers.
The actual costs of a FaaS are not limited to the time required to set up a function or write code, but cover other key components of a serverless network.
In terms of managed cloud solutions we need to take into account permission levels and other necessary cloud services, and then come up with a way to merge them all in a single unit.
Significantly more effort is needed to set up an open source FaaS, which requires knowledge about the backend server. It, however, offers less limitations than a managed solution.
How does it look in practice?
Let's get to the fun stuff. The code is available over at the following GitHub repository.
The AWS Lambda is a powerful Serverless platform that supports many programming languages.
In this particular scenario we will be using Python as I find it to be the easiest way to approach basic code. All Lambda functions will be executed over API Gateway - managed cloud solution for backend services - and CloudWatch Rule - simple cron schedule.
Scenario
The scenario assumes the following actors in the system:
- Trainer
- Student
- Scheduler
Based on actual scheduled sessions organized by the trainer with the students. Let’s agree to some conditions:
- Each meeting is scheduled on Tuesday and the session ends with the Trainer giving the Students some homework.
- Each homework is followed by a test containing questions.
- the test is available through a simple bash client (possibly a web page - I am not however a frontend developer).
- Each test can be completed only till Monday 11 PM, so the day before a new lesson.
- When a Student is ready to submit their answers, the bash client calls the API Gateway to store the results. This is when our pipeline runs (executes).
Pipeline details
The figure below demonstrates how the pipeline works. Each student activity calls the API Gateway and thus Lambda which is associated with the API endpoint.
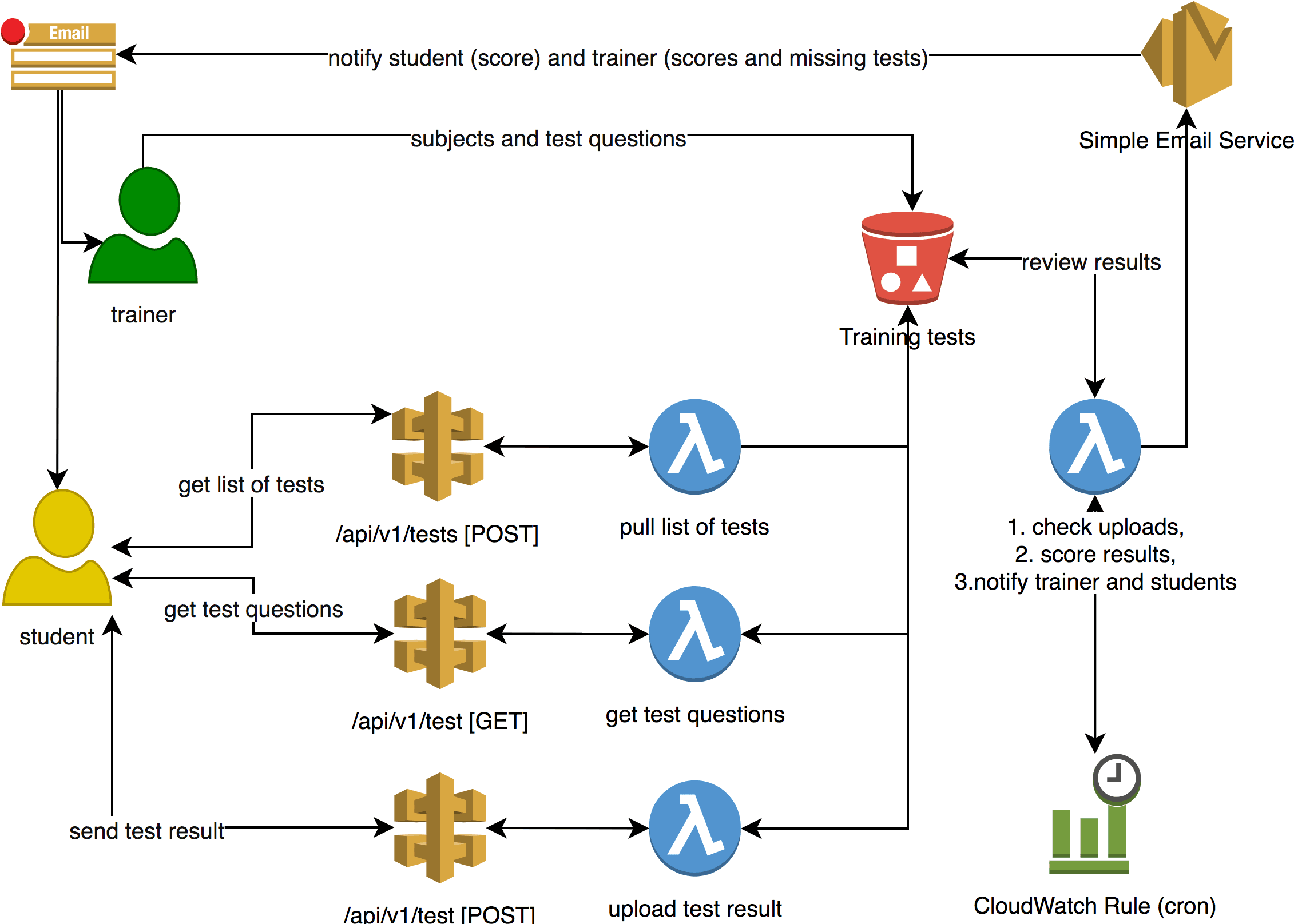
Endpoints:
- /api/v1/tests [POST] - pulls the list of tests for the student to fill (in case of multiple subjects) - request body requires 2 parameters: studentId and subjectName,
- /api/v1/test [GET] - pulls the test questions to fill - request querystring requires 2 parameters: subjectName and testId,
- /api/v1/test [POST] - uploads answers to AWS - request body requires 4 parameters: subjectName, testId, studentId and student answers.
In order for it to work with the APIs, the Trainer shares an API key with each of the students separately. An S3 bucket (encrypted with AES-256 to meet GDPR requirements) is used as a backend storage to save the list of Students and their submitted results.
How is the Serverless app deployed?
CloudFormation template
AWS offers the CloudFormation service in order to simply describe resources using templates, and then deploys these to AWS using stacks.
The code snippet below is a part of the CloudFormation template for Lambda to upload the test results to AWS
"UploadStudentTestLambdaFunction": {
"Type": "AWS::Lambda::Function",
"Properties": {
"Handler": {"Ref": "UploadStudentTestHandler"},
"Role": {"Fn::GetAtt": ["UploadStudentTestLambdaRole","Arn"]},
"Code": {
"S3Bucket": { "Ref": "BucketName" },
"S3Key": { "Ref": "UploadStudentTestBucketKey" }
},
"Environment" : {
"Variables": {
"targetBucketName": { "Ref": "TargetUploadS3Bucket" },
"studentAnswersKeyPath": { "Ref": "StudentAnswersS3BucketKey" }
}
},
"Runtime": "python3.6",
"Timeout": "60",
"FunctionName": { "Fn::Select" : [ "0", { "Fn::Split" : [ ".", { "Ref": "UploadStudentTestHandler" } ] } ] },
"Description": "Upload student test Lambda function"
}
}
Each resource is determined by Type. Lambda requires a couple of fields to be filled:
- FunctionName - name of AWS Lambda.
- Handler - the main function inside the code that runs said function - the default method for Python codes is lambda_handler(event,context).
The event variable holds the data about the trigger which executes the function and mapped content/body from the API Gateway. Context inherits the information about AWS metadata, like account ID, principal ID, region, etc.
- Code - S3 bucket and the key where the source code is available.
- Runtime - engine used by the source.
- Timeout (in seconds) - depends on the code execution time - the maximum value is 300 seconds so 5 minutes.
With CloudFormation we can create a map of the environment variables. In the case above, targetBucketName nad studentAnswersKeyPath will be mapped to such variables. The function to store the students tests requires specific access to the S3 bucket. For this reason, Role holds the name of Identity and Access Role holds permissions to the S3 bucket as write-only.
The Ansible Playbook
This is a configuration management tool, however, due to its large number of modules, it is often used to deploy and manage cloud infrastructure, which can be deployed within minutes.
It requires defining parameters for the playbook to use. All parameters are available under [groups_vars/all.yml].
Playbook deploys the AWS resources listen within the CloudFormation templates, then creates bundles (archives) for Lambda functions and prepares the S3 bucket to work with the API Gateways. A function with a CloudWatch rule is also deployed - every Monday at 11 pm the function collects the test results and generates scores, then notifies the students and the trainer.
./deploy-api-gateway.sh
TASK [include_tasks] ****************************************************************************************************************************************************************************
included: /Serverless_architecture/tasks/initialize-variables.yml for localhost
included: /Serverless_architecture/tasks/s3-create-bucket.yml for localhost
included: /Serverless_architecture/tasks/apigateway-deploy.yml for localhost
included: /Serverless_architecture/tasks/lambda-deploy.yml for localhost
...
TASK [Register CloudFormtion template name] *****************************************************************************************************************************************************
ok: [localhost]
TASK [Put CloudFormation template to S3 bucket | lambda-generate-student-test-score.template] ***************************************************************************************************
changed: [localhost]
TASK [Create AWS CloudFormation stack | lambda-trainings-tests] *********************************************************************************************************************************
changed: [localhost]
...
Below figure shows the state after the CloudFormation stack deployment.

Another playbook creates a [list of subjects] and tests every subject under the AWS S3 bucket.
This playbook can be executed by the trainer after every session with students. Mainly, the [list of students] is delivered to the S3 - only students on the list have access to homework.
./update-subjects-or-students.sh
Let’s do some homework ourselves
Under this [bin] directory you will find two scripts:
- pull-api-config.sh - which pulls the API endpoint URL and API key to make API requests,
./bin/pull-api-config.sh
_____ _ _ _____ _____ __ _
| __ \ | | | /\ | __ \_ _| / _(_)
| |__) | _| | | / \ | |__) || | ___ ___ _ __ | |_ _ __ _
| ___/ | | | | | / /\ \ | ___/ | | / __/ _ \| _ \| _| |/ _` |
| | | |_| | | | / ____ \| | _| |_ | (_| (_) | | | | | | | (_| |
|_| \__,_|_|_| /_/ \_\_| |_____| \___\___/|_| |_|_| |_|\__, |
__/ |
|___/ v0.1
author: [email protected]
API Endpoint URL: https://<api-id>.execute-api.<aws-region>.amazonaws.com
API Key: ********************
- test-time.sh - simple client to connect as student to API Gateway and fill tests.
./bin/test-time.sh
_______ _ _ _
|__ __| | | | | (_)
| | ___ ___| |_ | |_ _ _ __ ___ ___
| |/ _ \/ __| __| | __| | `_ ` _ \ / _ \
| | __/\__ \ |_ | |_| | | | | | | __/
|_|\___||___/\__| \__|_|_| |_| |_|\___| v0.1
author: [email protected]
---------------------------- [TEST] ------------------------------------
Subject: operating-systems
Test ID: test01
---------------------------- [TEST] ------------------------------------
[1] What is kernel?
a: kernel is the core component of an operating system
b: kernel is an web application
c: kernel is a web browser
d: none of the mentioned
Your answer: a
...
Your answer: a
[6] Which desktop environment is not used in any linux distribution?
a: gnome
b: kde
c: unity
d: none of the mentioned
Your answer: d
-------------------- [TEST UPLOAD] ---------------------
Test test01 uploaded with success
-------------------- [TEST UPLOAD] ---------------------
Notifications
As part of the pipeline, Lambda sends notifications using AWS Simple Email Service. A student is notified about their score for each test separately, if of course such a test has been submitted. The next figure shows an example message for the student (please disregard the same email address for the sender and received - I only have one account :))
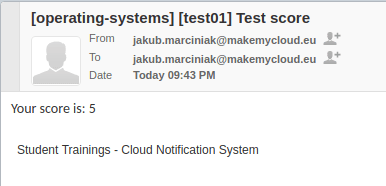
The second notification is sent to the Trainer. He receives a message with student grades and a list of missing results - which is a good opportunity to remind the students about their homework :)
By default, an AWS account has restricted access to SES. Users/services can only send emails to addresses registered within a validated list.

Serverless seems great, however...
Every technology comes with both advantages and disadvantages. An easy and cost efficient setup is an obvious profit. But there are limitation that make our life tough. AWS Lambda main depriment is a short time of execution - only 5 minutes. Should you require to run a code that is even slightly longer, you have to look to other services like Simple Queue Service. So a simple solution suddenly becomes needlessly difficult.
Most of all, it complicates the pipeline further and results in overhead costs. Another limitation of a Serverless managed cloud is requiring a unique setup for every specific cloud provider, which means that every time you need to deploy a function to AWS or GCP, you have to rewrite your code. The same applies to performance.
Summary
The pipeline described in this article should bring new experience with a Serverless managed cloud. The costs of maintaining a deployment use case equal zero. In case of high traffic and resulting number of request of connections, the costs stay at a few dollars per month.
We can still, however, ask ourselves is it really worth investing in a FaaS managed cloud? The answer is Yes. Even if there are many use cases where cloud limitations are somewhat strange. As an architect, I can attest that by estimating cloud costs, you can create a cheap but powerful infrastructure. The key is gaining knowledge about the cloud provider and their free tier usage plans :)
I encourage you to do your homework and create your own Serverless app.
About the author
Jakub Marciniak is a Founder of MakeMyCloud. Big fan and enthusiast of Cloud Native and Container Native technologies. Jakub believes that simple solutions bring higher value than ideal products. On a daily basis, he cooperates as DevOps Engineer with Ework customers.