

Parul PandeyData Science CommunicatorTowards Data Science, Analytics VIdhya, OpenSource.com
Przegląd pakietu Datatable Pythona
Poznaj pakiet Datatable Pythona, czyli bibliotekę do wydajnego wielowątkowego przetwarzania danych.
„Od początku cywilizacji do roku 2003 stworzono 5 eksabajtów informacji, ale tyle dziś tworzymy co każde dwa dni” - Eric Schmidt
Jeśli jesteś użytkownikiem R, istnieje prawdopodobieństwo, że korzystałeś już z pakietu data.table. Jest on rozszerzeniem pakietu data.frame w R. To najczęstszy wybór użytkowników R, jeśli chodzi o szybką agregację dużych danych (nawet do 100 GB w pamięci RAM).
Pakiet R data.table jest bardzo wszechstronnym i wydajnym pakietem ze względu na łatwość obsługi, wygodę i szybkość kodowania. Jest to dość znany pakiet w społeczności R, pobierany ponad 400 tysięcy razy w miesiącu i używany przez niemal 650 pakietów CRAN i Bioconductor.
Co więc oferuje użytkownikom Pythona? Dobrą wiadomością jest to, że istnieje również Pythonowy odpowiednik dla pakietu data.table o nazwie datatable, który koncentruje się na obsłudze dużych zbiorów danych i wysokiej wydajności, zarówno w operacjach w pamięci, jak i na zbiorach danych poza pamięcią oraz algorytmach wielowątkowych. W pewnym sensie można nazwać go młodszym bratem data.table.
Datatable

Nowoczesne aplikacje do uczenia maszynowego muszą przetwarzać dużą ilość danych i generować wiele atrybutów. Jest to konieczne, aby budować modele z większą dokładnością. Moduł Pythona datatable został stworzony w celu rozwiązania tego problemu. Jest to zestaw narzędzi do wykonywania operacji na dużych danych (do 100 GB), na maszynie z jednym węzłem, z maksymalną możliwą prędkością. Rozwój datatable jest sponsorowany przez H2O.ai, a pierwszym użytkownikiem datatable był Driverless.ai.
Ten zestaw narzędzi bardzo przypomina pandas, ale bardziej koncentruje się na szybkości i obsłudze dużych danych. Pythonowy datatable dąży również do zadowolenia użytkownika, pomocnych komunikatów o błędach i wydajnego API. W tym artykule zobaczymy, w jaki sposób możemy korzystać z datatable i jak wypada na tle Pandas, jeśli chodzi o duże zbiory danych.
Instalacja
W systemie MacOS datatable można łatwo zainstalować za pomocą pip:
pip install datatable
W systemie Linux instalacja jest realizowana przy użyciu dystrybucji binarnej w następujący sposób:
# Jeśli masz Pythona w wersji 3.5
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp35-cp35m-linux_x86_64.whl
Jeśli masz Pythona wersji 3.6
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp36-cp36m-linux_x86_64.whl
Obecnie datatable nie działa na systemach Windows, ale trwają prace aby dodać wsparcie również na Windowsa.
Aby uzyskać więcej informacji, rzuć okiem na Instrukcje budowania. Kod tego artykułu można uzyskać z tego repozytorium Github.
Czytanie danych
Używany zestaw danych został pobrany z Kaggle i należy do Lending Club Loan Dataset. Zestaw danych składa się z kompletnych danych kredytowych dla wszystkich pożyczek wydanych w latach 2007–2015, w tym aktualnego statusu pożyczki (bieżąca, spóźniona, w pełni opłacona itp.). Oraz najnowszych informacji o płatnościach. Plik składa się z 2,26 mln wierszy i 145 kolumn. Rozmiar danych jest idealny do zademonstrowania możliwości biblioteki datatable.
Importowanie niezbędnych bibliotek
import numpy as np
import pandas as pd
import datatable as dt
Załadujmy dane do obiektu Frame. Podstawową jednostką analizy w datatable jest Frame. Jest to to samo pojęcie, co pandas DataFrame lub tabela SQL: dane ułożone w dwuwymiarowej tablicy z wierszami i kolumnami.
Z datatable
%%time
datatable_df = dt.fread("data.csv")
____________________________________________________________________
CPU times: user 30 s, sys: 3.39 s, total: 33.4 s
Wall time: 23.6 s
Powyższa funkcja fread() ma duże możliwości i jest niezwykle szybka. Może automatycznie wykrywać i analizować parametry większości plików tekstowych, ładować dane z archiwów .zip lub adresów URL, czytać pliki Excel i wiele więcej.
Dodatkowo parser datatable:
- może automatycznie wykrywać separatory, nagłówki, typy kolumn, zasady cytowania itp.
- Może odczytywać dane z wielu źródeł, w tym pliku, adresu URL, powłoki, surowego tekstu, archiwów i globów.
- Zapewnia odczyt plików wielowątkowych dla maksymalnej prędkości
- Zawiera wskaźnik postępu podczas odczytu dużych plików
- Może odczytywać zarówno pliki zgodne z RFC4180, jak i niezgodne.
Z pandas
Teraz przekalkulujmy czas, jaki pandas potrzebuje na wczytanie tych samych plików.
%%time
pandas_df= pd.read_csv("data.csv")
___________________________________________________________
CPU times: user 47.5 s, sys: 12.1 s, total: 59.6 s
Wall time: 1min 4s
Wyniki pokazują, że datatable jest wyraźnie lepsze od pandas do czytania dużych zbiorów danych. Podczas gdy pandas potrzebuję więcej niż minuty, datatable robi to w sekundy.
Konwersja frame
Istniejący frame może być przekształcony ramkę danych w pandas czy numpy w następujący sposób:
numpy_df = datatable_df.to_numpy()
pandas_df = datatable_df.to_pandas()
Konwertujemy nasz frame na obiekt dataframe pandas i porównamy czas.
%%time
datatable_pandas = datatable_df.to_pandas()
___________________________________________________________________
CPU times: user 17.1 s, sys: 4 s, total: 21.1 s
Wall time: 21.4 s
Wygląda na to, że odczyt pliku jako frame datatable, a następnie przekształcenie go w dataframe pandasa, zajmuje mniej czasu, niż odczyt przez czysty dataframe pandasa. Dlatego dobrym pomysłem może być zaimportowanie dużego pliku danych za pośrednictwem datatable, a następnie przekonwertowanie go na pandasowy dataframe.
type(datatable_pandas)
___________________________________________________________________
pandas.core.frame.DataFramePodstawowe właściwości ramki
Przyjrzyjmy się niektórym z podstawowych właściwości ramki danych w datatable, które są podobne do właściwości pandas:
print(datatable_df.shape) # (nrows, ncols)
print(datatable_df.names[:5]) # top 5 column names
print(datatable_df.stypes[:5]) # column types(top 5)
______________________________________________________________
(2260668, 145)
('id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv')
(stype.bool8, stype.bool8, stype.int32, stype.int32, stype.float64)
Możemy również użyć polecenia head, aby wyświetlić górne wiersze „n”.
datatable_df.head(10)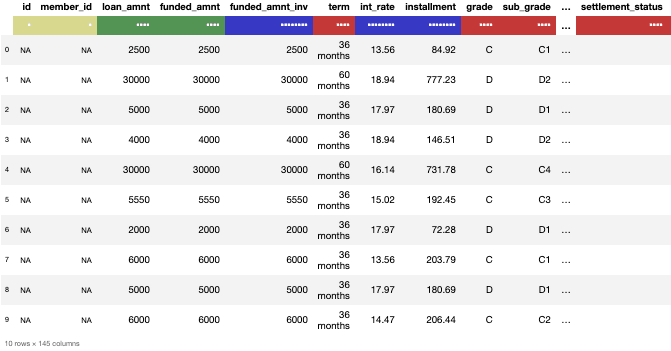 Rzut oka na pierwszych 10 wierszy datatable frame
Rzut oka na pierwszych 10 wierszy datatable frame
Kolor oznacza typ danych, gdzie czerwony oznacza string, zielony oznacza int, a niebieski oznacza float.
Statystyki podsumowujące
Obliczanie statystyk podsumowujących w pandas jest procesem pochłaniającym dużo pamięci. Inaczej jest z datatable. Możemy obliczyć następujące statystyki dla poszczególnych kolumn za pomocą datatable:
datatable_df.sum() datatable_df.nunique()
datatable_df.sd() datatable_df.max()
datatable_df.mode() datatable_df.min()
datatable_df.nmodal() datatable_df.mean()
Obliczmy średnią kolumn, używając zarówno datatable, jak i pandas, aby zmierzyć różnicę czasu.
Z datatable
%%time
datatable_df.mean()
_______________________________________________________________
CPU times: user 5.11 s, sys: 51.8 ms, total: 5.16 s
Wall time: 1.43 s
Z pandas
%%time
datatable_df.mean()
_______________________________________________________________
CPU times: user 5.11 s, sys: 51.8 ms, total: 5.16 s
Wall time: 1.43 s
Powyższe polecenie nie może zostać zakończone w pandas, ponieważ zaczyna zwracać błąd pamięci.
Manipulacja danymi
Datatable, jak dataframe’y, są kolumnowymi strukturami danych. W datatable podstawą wszystkich operacji jest notacja nawiasu kwadratowego, inspirowana tradycyjnym indeksowaniem macierzy, ale posiada więcej możliwości.
 notacja w nawiasie kwadratowym w Datatable
notacja w nawiasie kwadratowym w Datatable
Ta sama DT [i, j] jest używana w matematyce podczas indeksowania macierzy, w C/C++, w R, w pandas, w numpy itp. Zobaczmy, jak możemy wykonywać najczęstsze działania związane z manipulowaniem danymi przy użyciu datatable.
Wybieranie podzbiorów wierszy / kolumn
Poniższy kod wybiera wszystkie wiersze i kolumnę funded_amnt ze zbioru danych.
datatable_df[:,'funded_amnt']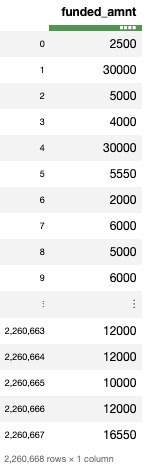
Oto, jak możemy wybrać pierwsze 5 wierszy i 3 kolumny
datatable_df[:5,:3]Sortowanie frame'u
Z datatable
Sortowanie frame'u według konkretnej kolumny można osiągnąć z datatable w następujący sposób:
%%time
datatable_df.sort('funded_amnt_inv')
_________________________________________________________________
CPU times: user 534 ms, sys: 67.9 ms, total: 602 ms
Wall time: 179 ms
Z pandas
%%time
pandas_df.sort_values(by = 'funded_amnt_inv')
___________________________________________________________________
CPU times: user 8.76 s, sys: 2.87 s, total: 11.6 s
Wall time: 12.4 s
Zwróć uwagę na znaczną różnicę czasu między datatable a pandas.
Usuwanie wierszy / kolumn
Oto sposób, w jaki możemy usunąć kolumnę o nazwie member_id:
del datatable_df[:, 'member_id']GroupBy
Podobnie jak w pandas, datatable ma również funkcje groupby. Zobaczmy, jak możemy wyliczyć średnią kolumny funded_amount zgrupowanej po kolumnie grade.
Z datatable
%%time
for i in range(100):
datatable_df[:, dt.sum(dt.f.funded_amnt), dt.by(dt.f.grade)]
____________________________________________________________________
CPU times: user 6.41 s, sys: 1.34 s, total: 7.76 s
Wall time: 2.42 s
Z pandas
%%time
for i in range(100):
pandas_df.groupby("grade")["funded_amnt"].sum()
____________________________________________________________________
CPU times: user 12.9 s, sys: 859 ms, total: 13.7 s
Wall time: 13.9 s
Co oznacza .f?
f oznacza frame proxy i zapewnia prosty sposób odwoływania się do ramki, na której obecnie pracujemy. W przypadku naszego przykładu dt.f oznacza po prostu dt_df.
Flitrowanie wierszy
Składnia filtrowania wierszy jest bardzo podobna do składni GroupBy. Przefiltrujmy wiersze loan_amnt, dla których wartości loan_amnt są większe niż wartość funded_amnt.
datatable_df[dt.f.loan_amnt>dt.f.funded_amnt,"loan_amnt"]Zapisywanie frame'u
Możliwe jest również zapisanie zawartości frame'u w pliku csv, aby można było z niego korzystać w przyszłości.
datatable_df.to_csv('output.csv')
Więcej informacji o funkcjach manipulacji danymi można znaleźć na stronie dokumentacji .
Wniosek
Moduł datatable zdecydowanie przyśpiesza pracę, zwłaszcza w porównaniu z pandas, i jest niesamowicie pomocny przy pracy z dużymi zestawami danych.
Należy jednak pamiętać, że datatable pozostaje w tyle względem pandasa pod kątem funkcjonalności. Ale zważając, że datatable jest wciąż rozwijany, w przyszłości możemy oczekiwać nowych funkcji i dodatków.
Referencje
- data.table R
- dokumentacja DataTable
- Wprowadzenie do datatable w Python: Wspaniały Kernel Kaggle o wykorzystaniu DataTable
Oryginał artykułu w języku angielskim możesz przeczytać tutaj.
