

Pranjal SaxenaData ScientistGenpact
7 najbardziej przydatnych one-linerów w Pythonie
Poznaj 7 przydatnych one-linerów Pythona, dzięki którym zaimportujesz m.in. wszystkie biblioteki za jednym razem.
1. Przechwytywanie tekstu z obrazu
pytesseract to biblioteka Pythona, która pomaga w odczytaniu tekstu z jakiegoś obrazu za pomocą jednej linijki kodu. Po pierwsze musimy odczytać obraz — wykorzystajmy do tego OpenCV.
Najpierw je zainstalujmy.
pip install opencv-python
pip install pytesseract
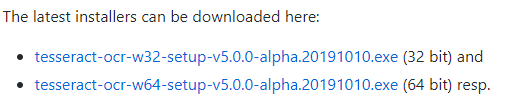
Musimy pobrać plik .exe, aby upewnić się, czy pytesseract dobrze działa na Twojej maszynie z Windowsem.
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = "YOUR_DOWNLOADED_FILE_PATH"
Jeśli powyższa komenda działa bez błędów, to oznacza to, że wszystko jest w porządku.
Załaduj obraz, a następnie odczytaj tekst, który na nim się znajduje w jednej linijce.
img = cv2.imread("YOUR_IMAGE_PATH")
text = pytesseract.image_to_string(img)
print(text)2. Import wszystkich bibliotek za jednym razem
pyforest to moduł Pythona, który pomoże nam zaimportować wszystkie biblioteki przy użyciu jednej linijki kodu. Możesz zaimportować każdą bibliotekę ogólnego użycia, w tym te wykorzystywane do zadań związanych z uczeniem maszynowym. Biblioteka ta ma też trochę modułów pomocniczych, takich jak os, tqdm, re, i wiele więcej.
pip install pyforest
Aby sprawdzić listę bibliotek, uruchom dir(pyforest).
Po zaimportowaniu pyforest możesz uruchomić pd.read_csv() , sns.barplot() , os.chdir() i wiele więcej.
3. Generowanie raportu o danych
pandas_profiling to biblioteka Pythona, która może nam pomóc w uzyskaniu raportu o danych i to w przeciągu kilku sekund. Raport można sobie pobrać do dalszego użycia.
pip install pandas_profiling
Po instalacji biblioteki zaimportuj ją tak jak poniżej:
import pandas_profiling
import pandas as pd
Korzystamy z Pandas do zaimportowania zestawu danych.

Import danych
 Zdjęcie danych
Zdjęcie danych
hourse_price_report=pandas_profiling.ProfileReport(df).to_file('house_report.html')
Twój raport zostanie zapisany jako plik HTML.
Więcej zdjęć raportu danych:
 Podsumowanie danych
Podsumowanie danych
Szczegółowe informacje na temat każdej ze zmiennych
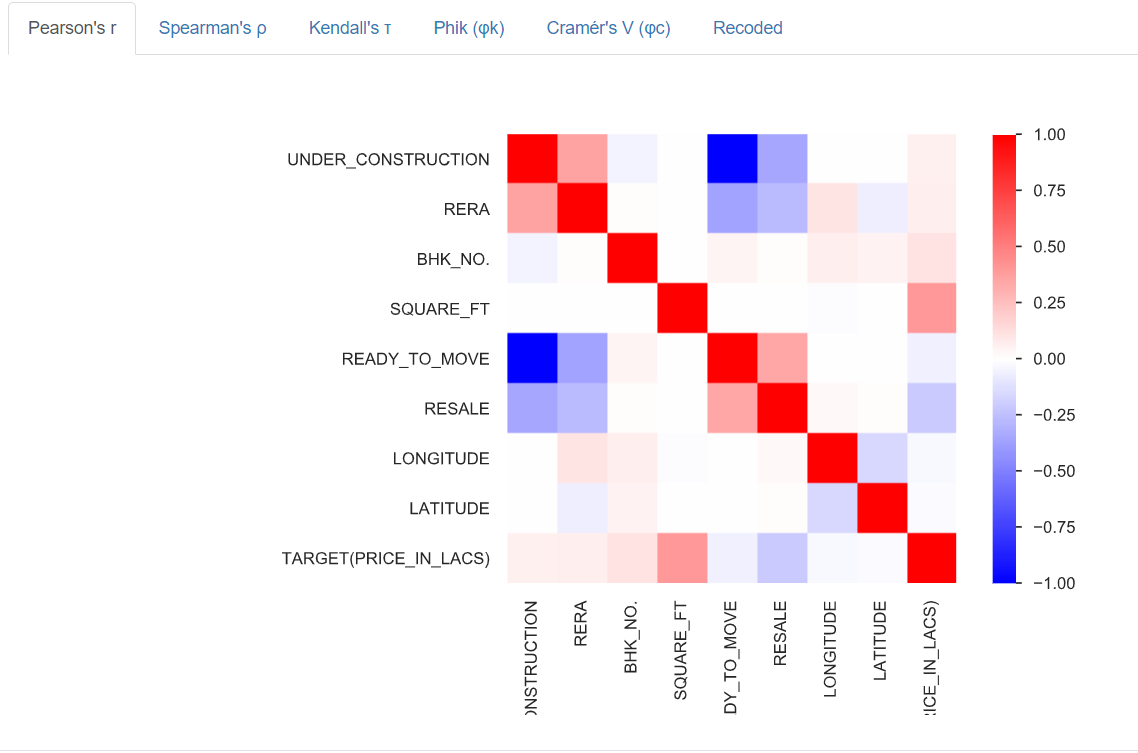
Szczegółowa wizualizacja dla każdej korelacji pośród zmiennych
4. Łączenie dwóch słowników
Jeśli masz dwa słowniki dic1 i dic2 i chcesz, żeby pary klucz-wartość zostały przeniesione z dic2 do dic1, to poniższa linijka kodu Ci w tym pomoże.
dic1.update(dic2)5. Przekonwertuj listę ciągów znaków na liczby całkowite
Metoda ta przydaje się, gdy bierzemy wejście od użytkownika, które wprowadzane jest jako ciąg znaków. Poniższa linijka Pythona może go przekonwertować na liczby całkowite.
list(map(int, ['1', '2', '3']))
Wyjście: [1, 2, 3]
6. Web scraping
Web scraping to nic ciężkiego, ale dokonanie transformacji, tego co udało nam się uzyskać, to żmudne zadanie. Poniżej zobaczysz, jak wydobywam dane o bitcoinach z Wikipedii.
import pandas as pd
data = pd.read_html(“https://en.wikipedia.org/wiki/Bitcoin")
A teraz możemy pobawić się ze zmienną data, aby wydobyć pożądane informacje.
7. Przyspiesz operacje Pandas
modin to biblioteka Pythona, która wykorzystuje Ray lub Dask, aby zapewnić łatwy sposób na przyspieszenie notebooków, skryptów i bibliotek Pandas.
Wykorzystaj poniższą linijkę kodu do instalacji modin.
pip install modin
A teraz można to zainstalować w następujący sposób.
import modin.pandas as pd
To wszystko, co musisz zrobić — nie potrzeba więcej linijek kodu.
Podsumowanie
To by było na tyle. Omówiliśmy tutaj kilka bardzo przydatnych one-linerów. Niektóre z nich są naprawdę przydatne - pyforest pomaga w zainstalowaniu wszystkich bibliotek naraz, a modin przyśpieszy wszystkie operacje związane z Pandas, w tym czytanie data frame’ów i wprowadzanie zmian.
Mam nadzieję, że ten artykuł się przyda. Dziękuję za uwagę!
Oryginał tekstu w języku angielskim możesz przeczytać tutaj.
