

Bulldogjob
Kiedy machine learning ma sens?
Kiedy i dlaczego uczenie maszynowe się sprawdza, a kiedy jest to sztuka dla sztuki?
AI, deep learning, machine learning - gorące tematy, które coraz śmielej wkraczają w nasze życie. Problem polega na tym, że często są traktowane jak kolejne buzzwords, słowa wytrychy - a nie techniki inżynierskiego rozwiązywania problemów. Dzisiaj zastanowimy się, kiedy uczenie maszynowe ma sens, a kiedy jest rozwiązaniem zrobionym na siłę.
Czym jest machine learning?
Sam termin ukuł Arthur Samuel w 1959 roku, a jego definicja zawężała AI do wymiaru uczenia się maszyn:
Machine Learning to zdolność komputerów do uczenia się bez programowania nowych umiejętności wprost.
W praktyce oznacza to algorytmy, które przetwarzając dane uczą się z nich, a przy podejmowaniu decyzji stosują to, czego się nauczyły.
Rozwinięciem machine learning jest deep learning, czyli uczenie maszynowe oparte na sieciach neuronowych. W ciągu ostatnich 60 lat wypracowano mnóstwo algorytmów i rozwiązano bardzo wiele problemów bez stosowania sieci neuronowych, a teraz zastosowanie sieci jest o wiele prostsze niż kiedykolwiek - głównie dzięki frameworkom AI, takim jak TensorFlow, czy silnikom AI dostępnym w chmurze - Google AutoML, Amazon ML, czy Azure ML Studio.
Jakiej klasy problemy może rozwiązać?
Podzielimy typowe problemy ML na 4 kategorie: klasyfikacja (ang. classification), regresja (ang. regression), klasteryzacja (ang. clustering) oraz redukcja wymiarów (ang. dimensionality reduction) - proponuje nasz ekspert od ML, Ruslan Korniichuk z Capgemini - Osobiście pracuję z klasyfikacją, regresją oraz klasteryzacją - dodaje. By lepiej zrozumieć o co chodzi, omówimy każdą z kategorii.
Klasyfikacja
Przydzielenie obserwacji do prawidłowej kategorii na podstawie wybranych cech. Klasycznym przykładem jest filtr spamowy, który musi zdecydować czy wiadomość jest spamem, czy nie. Jest to technika uczenia nadzorowanego.
Regresja
Proces, podczas którego ustala się związek pomiędzy zmiennymi. Dostarcza informacji o tym, czy są to zmienne zależne, czy niezależne. Dzięki temu można przewidywać zachowania w przyszłości.
Klasteryzacja
Grupowanie danych według pewnych cech w klastry o podobnych właściwościach. Zauważyliście pewnie, że w zasadzie klasteryzacja jest jak kategoryzacja. Różnica tkwi w użyciu nienadzorowanego uczenia - oznacza to, że nie trzeba definiować wcześniej klastrów.
Redukcja wymiarów
Odrzucenie losowych zmiennych i pozostawienie tylko tych, które będą przydatne w dalszym przetwarzaniu. Redukcję można podzielić na selekcję cech (czyli odrzucenie informacji nadmiarowej, czy tej, która jest bez znaczenia) - i ekstrakcję cech (czyli wyszukanie w zbiorze cech pożądanych).
Nie brzmi to wszystko jak coś, co zmienia życie, prawda?
Kiedy machine learning jest korzystny?
Uczenie maszynowe będzie lepsze od klasycznego rozwiązania, gdy nie można zapisać reguł, które będą dobrze działały i skala problemu jest zbyt duża, by go manualnie rozwiązać. Ciężko zapisać reguły, gdy zmiennych, które potencjalnie wpływają na wynik, jest dużo, a reguły w pewnym stopniu się nakładają.
Wykorzystanie technik ML będzie wtedy miało sporo zalet. - Zwykle ML ma zapewnić zwiększenie efektywności, wydajności, bezawaryjności - mówi Ruslan Korniichuk - Konkretne korzyści zależą od projektu.
Robiliśmy projekt lead scoringu opartego na bazie mailingowej oraz statystykach dla każdego adresu e-mail. Na wyjściu jest klasyfikator siły nabywczej leadów dla nowej wiadomości reklamowej - gdzie 0 oznacza ,,nie kupi’’, a 1 ,,kupi’’. Tu uzyskaliśmy zwiększenie skuteczności marketingowej i sprzedażowej poprzez precyzyjne dopasowanie treści, a finalnie zwiększenie dochodów - kontynuuje.
Innym przykładem był ticket routing dla zgłoszeń odebranych przez service desk. Z grubsza: ,,kieruj do Działu Płac’’, ,,kieruj do HR’’ lub ,,kieruj do Service Desk’’. Tu chodziło o zapobieganie rutynowej, powtarzalnej pracy, błędom ludzkim i uniknięcie dodatkowych kosztów licencji oprogramowania - dodaje.
A kiedy sprawia problemy?
Z praktycznego punktu widzenia najczęściej problemem będzie ilość i jakość danych. Wytrenowanie algorytmu może nie być możliwe, gdy będzie ich mało, nie będą reprezentatywne lub będą mocno zaszumione. W takich przypadkach trzeba się zastanowić nad zastosowaniem podejścia opartego na regułach.
Trzeba pamiętać, że machine learning nie naprawi danych, jeżeli ich jakość nie jest wystarczająca. Podobny problem występuje w big data - nie wystarczy mieć ,,jakieś’’ dane, trzeba mieć dane dobre.
Dodatkowo z samego uczenia maszynowego wynika sporo problemów. Więcej na ten temat powie nasz ekspert z Capgemini:
ML ma dużo znanych ograniczeń: etykietowanie danych (ang. labeling), objętość danych (ang. volume), problem wyjaśnienia (ang. explainability), uogólnianie uczenia się (ang. generalizability).
Dla każdego problemu mamy jednak rozwiązania:
- Etykietowanie danych: uczenie przez wzmacnianie, generative adversarial networks (GANs).
- Objętość danych: one-shot learning.
- Problem wyjaśnienia: local-interpretable-model-agnostic explanations (LIME), techniki uwagi (attention).
- Problem uogólnienia: transfer learning
Często też dla problemów, którymi może zająć się ML istnieją dobre alternatywy w postaci tradycyjnych algorytmów.
W projekcie lead scoringu nieco zabawne było, gdy uzyskaliśmy wysoką dokładność (ang. accuracy score) losowo wybieranego algorytmu. Wybierał on adresy do wysyłania maili marketingowych. Algorytm był znacznie lepszy od całego zespołu złożonego z ludzi na etatach, którzy robili to po swojemu i bez żadnych metryk. ML w tym przypadku można było zastąpić algorytmem top class. Algorytm do każdej wiadomości proponowałby tylko klientów z największą historią zakupów. Jeżeli będziemy uważać na częstotliwość wysyłania takich maili, mamy całkiem dobry algorytm - bez GMO, glutenu oraz ML. :)
Do ticket routingu też można było użyć algorytmu top class, bo jedna z kategorii zawierała powyżej 80% wszystkich ticketów. Wtedy mamy dokładność na poziomie 80%. Inna możliwa, ale kosztowna alternatywa to rozwiązania od producentów oprogramowania dla Service Desk.
To stosować czy nie?
Jasne, że stosować, ale najlepiej wtedy, gdy rozwiązania tradycyjne nie dają satysfakcjonującego rezultatu. Użycie uczenia maszynowego nie może być czymś domyślnym - powinno wynikać z inżynierskiej potrzeby.
Również dlatego, że złe zastosowanie ML może generować duże, niepotrzebne koszty. Często nie chodzi nawet o samo użycie uczenia maszynowego, które może mieć jak najbardziej rację bytu, ale o to, jakie techniki i w jaki sposób zostały zastosowane. Często niewielka zmiana podejścia pozwala zaoszczędzić bardzo dużo czasu i pieniędzy. Doświadczenie pozwoli wychwycić, gdzie potrzebna jest zmiana.
Co ciekawe, możliwość zastosowania ML zależy również od branży klienta.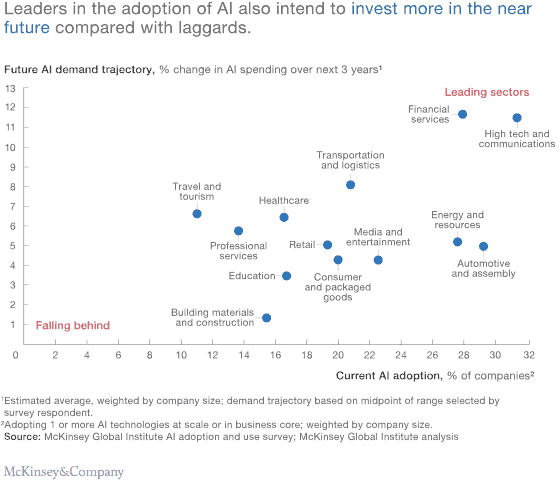
ML - jako dziedzina - wchodzi w skład sztucznej inteligencji. Adaptacja sztucznej inteligencji jest nierównomiernie rozłożona pomiędzy branżami (zobacz rysunek). Oczywiście, że chcemy wpływać na rozwój ML. Gdy nasz klient jest z branży usług finansowych lub z branży nowych technologii oraz komunikacji często mamy do czynienia z dużymi budżetami R&D i możemy proponować odważniejsze rozwiązania. Branżom, które pozostają nieco ,,z tyłu’’, nie pomoże tylko zastrzyk gotówki na badania. Musimy wybierać wyłącznie sprawdzone algorytmy i mocno ograniczyć koszty wydane na licencje oprogramowania - zauważa Ruslan Korniichuk.
Jeżeli więc wystąpi zgodność w kwestiach inżynierskich i ekonomicznych, jak najbardziej warto zainteresować się ML. Nawet jeżeli nie pracujesz jako ekspert od uczenia maszynowego, warto dowiedzieć się o nim nieco więcej - i może w wolnej chwili wypróbować te techniki.
Senior ITS Consultant w Capgemini. Były Python Developer oraz Data Engineer w firmach F500. Doktorant Uniwersytetu Śląskiego w Katowicach. Główne obszary: Software Development, Big Data.
