Database tuning

Database configuration for high efficiency requires every time a bit different measures and experiments. In that event, we’ll benefit from an environment that will, on the one hand, make these changes easier and, on the other, enable to smoothly apply these changes into production. AWS RDS (Amazon Relational Database Service) is one of these environments, where you can run most popular databases (MySQL, PostgreSQL, SQL Server, MariaDB, Oracle).
Tuning AWS RDS
RDS is an AWS isolated service for databases that stands on EC2. There is no config file access to configure the database. Instead, AWS provides a web panel that allows to create configuration groups.
If you use RDS, you use configuration groups as well. Each database creates a default read-only group that contains all of the parameters. To change this group into a different one, you need to do it at RDS view and restart the database. What is important - do that before you start using the database. Otherwise, prepare yourself for a short break in operation.
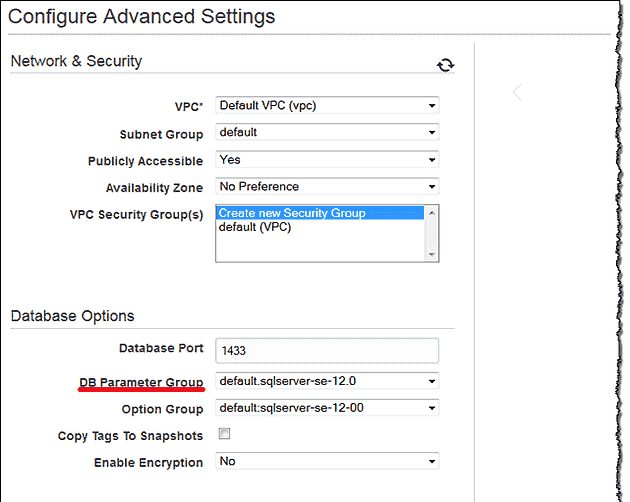
To create a group with custom parameters, go to: https://console.aws.amazon.com/rds/.
Click Parameter Groups in the Navigation List on the left side of the window. Then click Create Group.
Name - any name
Family - database type
In case of 1 master and 2 replicas, each server can have a different group attached.
When using configuration, you always need to restart the database. If you are using AWS parameter groups, there are two kinds of parameters: dynamic and static. The use of dynamic parameters doesn’t require database restart, while for static parameters the restart is necessary.
There is also a flag telling if particular parameter is editable.
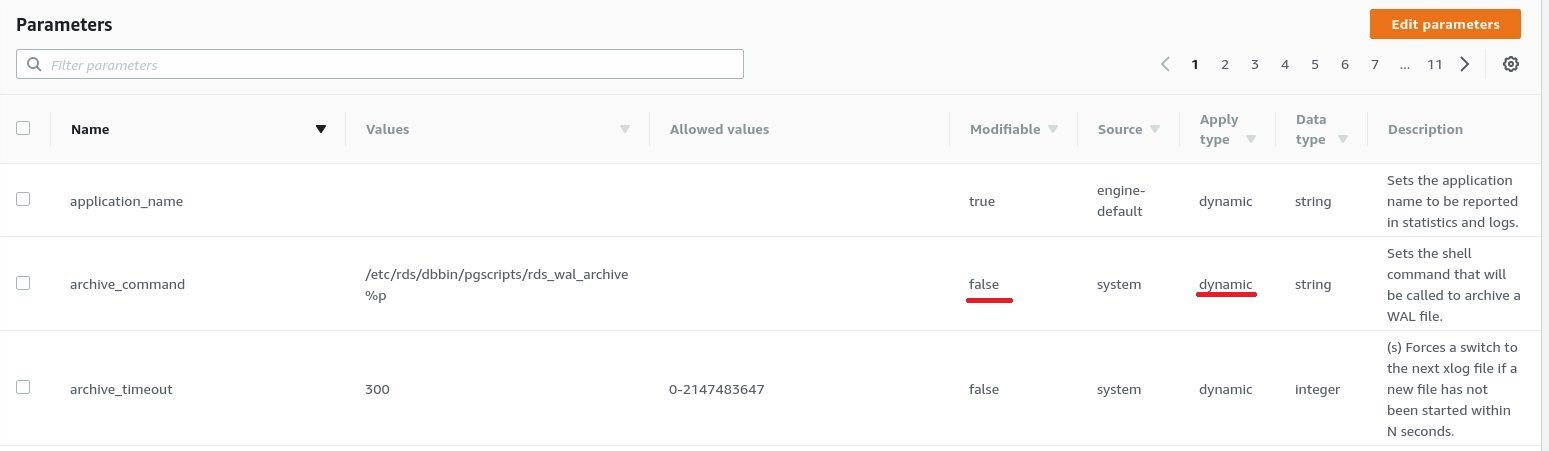
AWS also limits parameter values and provides default parameter values according to the database instance type (amount of ram).
Besides the web layout, there is also a way to use AWS parameter groups using console, but I haven’t found a use-case for it yet.
Conclusions
The use of parameter groups for configuring the database is an AWS solution built in RDS. Standalone database on custom server - or even AWS EC2 instance - requires file configuration. For that purpose, you have to log in to the server via console and find a configuration file. After that, parameters can be edited using console text editor. It makes the work with parameter groups in AWS more comfortable and faster. Another advantage is that there can be more than one parameter group - one active and the other inactive. It allows to test new configurations and gives a possibility to do a fast rollback. Sometimes wrong parameters can shut down database server process. In such situations, fast rollback allows to save money and customers.
Tuning up PostgreSQL
Like all popular relational databases, PostgreSQL has a configuration file that enables to customize the database.
This file has a variety of default values which are sufficient in most cases. They shouldn’t be changed, unless we know what they do. Tuning up can bring benefits or lead to a failure. I would like to describe some of the useful settings for PostgreSQL.
Memory
Setting up memcache allows to speed up queries and maintenance. Disks are much slower than RAM therefore, storing data in RAM allows to make the same operations finish faster. In PostgreSQL it is possible to do that using a few variables. It is important to set them correctly - in other case, the database will consume all your RAM, then SWAP and in the end – fall. If a big part of RAM is not used on the database server, there should be some tunning parameters applied. For safe use of database with custom parameters, database should run alone on a server or as a service.
There is a useful website for calculating better memory usage parameters than the ones available in the configuration file or AWS parameters. Default values are often too low. In most cases, using values given by the website is enough. For better tunning, some knowledge is required.
max_connections(int) - limit of concurrent connections. Each query makes a connection. After this limit is achieved, no connection can be made unless some connection ends. Each connection consumes RAM. Raising it up is useful when there is a big traffic - many concurrent connections to the database.
shared_buffers(int) - variable that determines how much memory is dedicated to PostgreSQL for caching data. Each query result goes to cache, so after rerun it's being served directly from RAM instead of hard drive. Good for many repeatable queries. More RAM = more queries result can be stored in it.
effective_cache_size(int) - limit of RAM for PostgreSQL. Query planner information on how much memory can be consumed. It checks if there is enough memory to use indexes. If not, sequential query is performed. It is great for databases having tables with many indexes.
work_mem(int) - determines how much RAM sort operations can consume. When there are many queries and sort operations running at the same time, RAM can be rapidly consumed. This value should be small, it could stack very fast and consume most of RAM. When the system using the database allows to perform many sort operations, for example, sort by name, sort by city, this value should be raised.
maintenance_work_mem(int) - memory limit for operations like: VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY. Good for databases with a lot of delete operations or when table schemes change often. For delete operations, the space allocated for deleted records becomes free faster. For changing scheme processes, table alters and unlocks faster. Altering big tables takes more time and lock during scheme migration creates a lock that kills all queries to the table. This parameter is very useful because when set correctly, it makes table available again faster.
Replication
This section applies when you have at least one replica. Some settings of the replication work only on master server, others - on slave server.
WAL - at all times, PostgreSQL maintains a write-ahead log (WAL). The log records every change that was made in the database's data files. Master writes to WAL and slave/slaves read/s from it to perform replication.
min_wal_size(int) - as long as WAL disk usage stays below this threshold, old WAL files are always recycled for future use at a checkpoint, rather than removed.
max_wal_size(int) - maximum size that WAL is allowed to reach between automatic WAL checkpoints.
checkpoint_completion_target(float) - specifies the target of checkpoint completion, as a fraction of total time between checkpoints.
wal_buffers(int) - the amount of shared memory used for WAL data that hasn’t been saved on a disk yet. The content of the WAL buffers is written out to a disk at every transaction commit. Therefore, extremely large values are unlikely to provide a significant benefit.
hot_standby(bool) - specifies whether or not you can connect and run queries during recovery.
When replica has long running queries, it should be set to true. Otherwise, queries will be killed after some time. PostgreSQL will decide that the data is not consistent. In case of many quick queries on replica, it could cause replication lag. This variable is only accessible on replica. It should be set only when replica perform long running queries.
max_standby_archive_delay (int) - when hot_standby is active, this parameter determines how long the standby server should wait before cancelling standby queries that fall afoul of about-to-be-applied WAL. In practical terms, this parameter determines how long to wait with stopping the query after the WAL update. This variable is only accessible on replica. Bigger value gives a possibility to run longer queries but also causes a bigger replica lag.
max_standby_streaming_delay (int) – similar to the parameter above, the only difference is that the delay in this case starts when replica receives the data.
In max_standby_archive_delay delay starts when replica starts to read the incoming data. Both variables should have similar values. This variable is only accessible on replica.
Replica lag – a period of time specifying how much data on the replica is out of date according to the master. The less, the better. On big databases load can grow very fast.
Other
pg_statistic – catalog where PostgreSQL stores statistics. Determines how to perform a query by planner to run it as fast as possible on the basis of available resources.
default_statistics_target(int) - the limit of entries stored in pg_statistic. Increasing the limit might allow to make more accurate planner estimates, at the price of consuming more space in pg_statistic and slightly longer time needed to compute the estimates.
random_page_cost(float) - determines planner's estimate of the cost of a non-sequentially-fetched disk page. Lower value of this parameter is better for SSD discs. Setting it low causes more frequent use of indexes.
seq_page_cost(float) - sets planner's estimate of the cost of a disk page fetch that is part of a series of sequential fetches. It is connected with random_page_cost. There is no need to change it when random_page_cost was changed.
Conclusions
When I first came across these properties, I decided to tune everything up - make database faster and allow queries to run longer. After the hype phase, here came the pain. The whole RAM was consumed in minutes. Tuning variables mentioned in this article should be a slow, gradual process. PostgreSQL has its parameters set to low default values to keep any database safe. Modifying these variables requires patience and several experiments. In many cases, the database works better when its parameters are set to lower values.
Not all variables consume RAM. Those connected with hot_standby can cause replication lags delaying your replica more and more, according to master.
AWS RDS allows to make experiments with parameters much faster and safer. Some of the parameters can cause side effects after some time, so after testing new parameter settings, the database needs to be monitored.
There are much more parameters that could be set, they all are well presented on this website:
https://demo.pganalyze.com/databases/6/config