Serverless - what is it and how does it work?

Serverless is, in short, a cloud services model in which the developer/architect focuses solely on creating the business logic and not on the infrastructure on which it is to be executed. The term serverless architecture might suggest that there are no servers at all. This is obviously untrue - the servers physically exist. The point is that a developer who creates a serverless solution does not have to deal at all with setting up machines, updating operating systems, configuring networks, scaling applications. This is the responsibility of the provider of the serverless service in question, i.e. Amazon, Microsoft, Google, for example. Every major public cloud provider has what we might call serverless services available.
What conditions does the service have to meet to be worthy of this name? In my opinion, there are several:
- Zero administration of infrastructure
- Automatic scaling of the service as load increases
- Payment for actual resources used, no need for "upfront" costs
The potential advantages of such solutions are apparent at first glance - reduced operating costs, greater flexibility and dynamism in the software development process, and thus faster delivery of value in the form of new application/system functionality.
Servers, kangaroos, dollars
One of the more spectacular stories in which serverless played a central role involves a project carried out by IBM for the Australian Bureau of Statistics on the occasion of the five-yearly general census. The main component of the system being developed was a web application that gave citizens the ability to fill out an online survey and add their data to the census. The cost of the project - about $10 million, of which more than $400,000 budgeted for tests to prepare the system for a load of one million page views per hour. This turned out to be not enough - in the evening, the same day after the system was launched, the application stopped responding to user queries. It was shut down, and it took more than 24 hours to restore operations.
A week after the event, two students created a project called "Make Census Great Again" during one of the weekend hackathons. In 24 hours, they created a copy of the system to conduct the census online - using serverless services available on Amazon Web Services (AWS Lambda, S3). The application passed tests successfully simulating a load four times greater than that assumed on the "official" system - all on a budget of less than $500 (read an interview with one of the developers).
Of course, one must maintain a healthy skepticism when evaluating this story - the devil is in the details, and we don't know those regarding the tender for the above-described system. Two conclusions can be made for sure:
- The system could have been done cheaper and better prepared for the increased load
- Serverless services can achieve highly scalable solutions with low time/money investment
And it was supposed to be so beautiful...
Since it's so fast and cheap - what's the catch? Here's a bucket of cold water straight from Twitter:
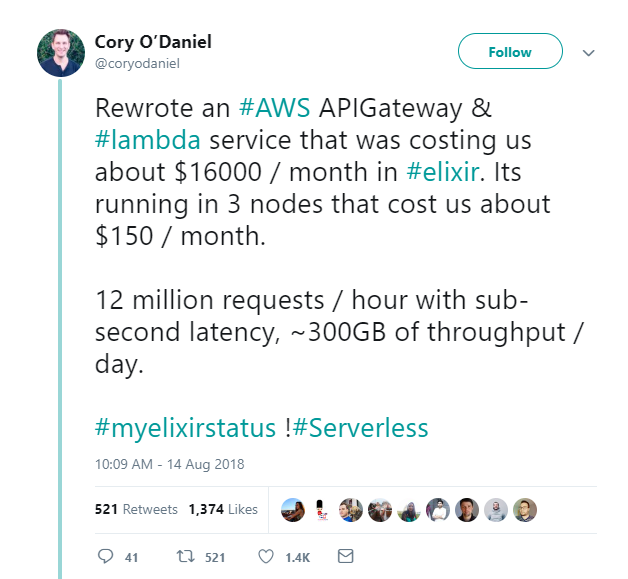
In a nutshell: the service was composed entirely of serverless solutions. Performance and scalability were not the problem - rising costs were. The part that generated the most of them was rewritten from NodeJS to Elixir and deployed on a kubernetes cluster, where it successfully handles a load of up to 12 million requests per hour - at a fraction of the previous cost. You can read about the details of the story behind the above tweet here.
Serverless services are therefore not a magical solution to all problems, and when using them, one should be aware of their limitations. There is a risk that costs can quickly get out of our control (due to inaccurate estimates, programming errors). It is also a common criticism that when we choose a particular service we bind ourselves very tightly to a particular provider. If so-called vendor lock-in is an issue, you might want to take a look at the open source framework Serverless, which is a layer of abstraction above provider-specific services. I'm not talking about general cloud-skeptic concerns - about where to store data or sharing an environment with other cloud users.
In this case - when to use serverless? The answer to such a question - as usual in our industry - is:
It depends.
Serverless solutions work well for writing prototypes, MVP, Proof of Concept - with small loads, they generate virtually no costs, and on top of that, they are ready to "accept" production loads at any time.
Services in which we see frequent, unpredictable load spikes will also be good candidates for implementation using serverless solutions. So are actions performed at regular intervals (e.g., cron jobs).
For applications running with a uniformly heavy load, the use of serverless services will not be cost-optimal. However, one must always consider the price not only of the infrastructure itself, but also of the work of the people who manage it - in each company/team this calculation will be different.
Cases where serverless services are leading the way are certainly stateless microservices, data processing (queues, images, video), handling events triggered by IoT devices, for example.
Serverless features are also ideal for integrating different SaaS systems/applications. They are often like the silver tape and tie wrap in a do-it-yourselfer's arsenal - easy to use and deadly effective :)
Hello, Serverless World!
I encourage you to check out these solutions in practice - either Microsoft Azure, Amazon Web Services, and Google Cloud Platform offer accounts that allow you to see virtually the entire range of services without spending a penny. It's worth starting with FaaS (Function as a Service) services - Azure Functions, AWS Lambda, Google Cloud Functions - for all of them it's easy to find descriptions of functionality, supported languages and ready-made examples in official documentation. You will quickly see that it is not a toy - on the contrary, in the hands of a mindful developer it can be a powerful tool.