Llama 3 outperforms... most open LLMs

Meta has announced the release of another version of its already popular LLM - Llama 3. It is presented as the most capable openly available LLM to date.
On the release day, Meta launched two variants of the model: 8B and 70B. Currently, only text mode is available, but in the background a 400B model is being trained.
What are the traits od Llama 3?
According to Meta's blog post, Llama 3 shows promising results in many aspects. The model demonstrates greater diversity in responses to questions, less frequently refusing to provide an answer, and has better inferencing abilities compared to Llama 2.
This version also has a better understanding of instructions and handles code writing better than its predecessor. Llama 3 can consider a context of up to 8k tokens, which is progress compared to the previous version where the maximum context was 4k tokens.
Models competing with Llama 8B often have similar context lengths, while those competing with Llama 70B support longer contexts, so not all of Meta's models excel in every aspect.
Llama 3 is a text model that performs exceptionally well in the English language, but struggles in other languages,
Model capabilities
According to tests results provided by Meta, Llama 3 outperforms many other artificial intelligence models, including Google's Gemini, Mistral 7B, and Claude 3 by Anthropic.
The 8B model competes with models of similar sizes, providing better results in many tasks. The 70B variant of the Llama 3 model is competitive with many commercial models, such as Gemini Pro or Claude Sonnet. Meta prepared the following benchmarks to confirm this:
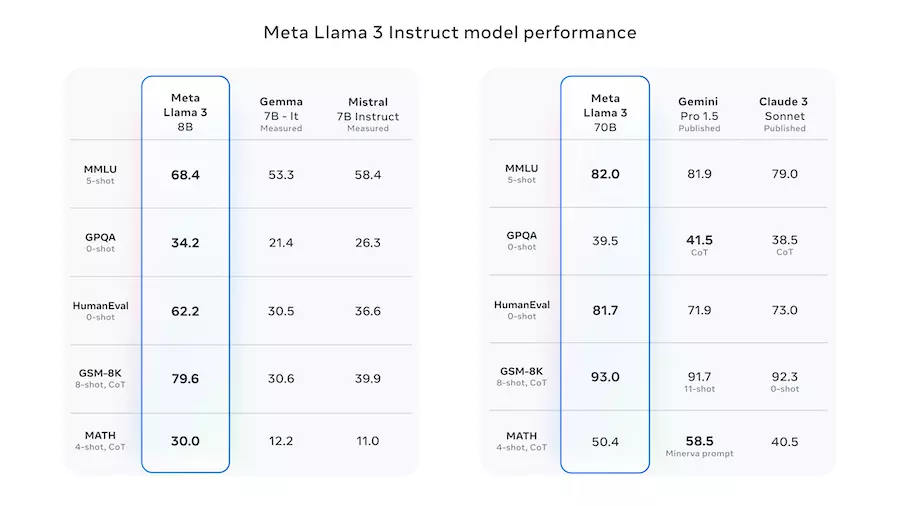
[source: https://ai.meta.com/blog/meta-llama-3/]
As seen, the 8B model performs excellently in the presented benchmarks. Meanwhile, the 70B version is very comparable to the competition.
Furthermore, Meta created its own benchmark where the response was evaluated by humans:
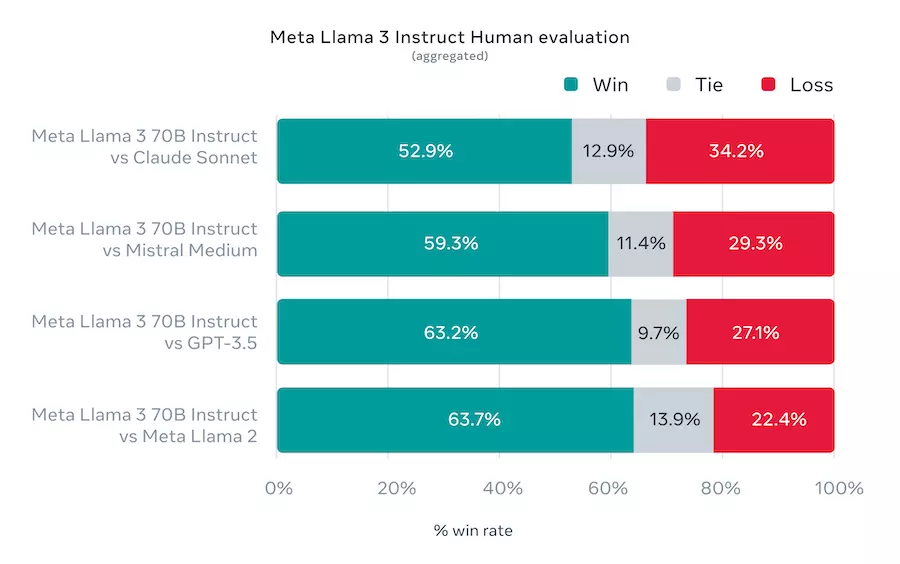
[source: https://ai.meta.com/blog/meta-llama-3/]
In this way, they suggest that Llama 3 70B is better than GPT 3.5.
Llama 3 development process
As always, the question arises: 'On what data was the model trained?' As always, the official answer is 'on publicly available high-quality sources.' In total, 15 billion tokens were used for training. 95% of this data was in the English language, hence the model does not perform very well in other languages. Meta claims that they spent a lot of time filtering input data to find the right balance in the training dataset. As a result, Llama 3 is expected to perform well not only in providing facts but also in tasks like coding.
A key element in improving the model was changing the tokenizer and adjusting the training to focus the attention mechanism on one topic at a time. This allowed for better results in text generation tasks.
Security and human evaluation
One of the significant aspects of the new model is its security. Meta has devoted considerable attention to describing security mechanisms within the model, especially those sensitive to topics related to biology, chemistry, and cybersecurity. The model is supposed to assess both input and output for safety.
The company also created a new dataset for human evaluation of the model, emulating scenarios of real-world usage of Llama 3. In this evaluation, the model achieved better results than competitive models, including GPT-3.5 from OpenAI.
In their materials, Meta encourages building applications based on the new models, stating that thanks to the new security measures, it will be the most suitable foundation model in many cases.
What's Next?
Although Llama 3 has already been published, there is still much to be done. Primarily, a detailed technical report on the models has not been published yet. It is expected to be released within the next few months.
The company assures us there is much more to come. Llama 3 is currently a text-only model, but this is expected to change soon. The models are to become multimodal - it is yet unknown whether Meta will focus on image or sound mode first.
The Llama 3 family is to be complemented by a large 400B parameter model. This version is currently being trained, and Meta has shared preliminary benchmark results. They are not directly compared to any existing models, but they are around those generated by GPT-4 at the time of release.
If you are building AI applications, it will be quite easy to test the new model since it is available everywhere. It can already be deployed at all major cloud providers. It is available on Kaggle or Hugging Face. You can also request access to the model directly from Meta via this link.